如何从0到1构建benchmark
AI的性能突飞猛进,背后各类的benchmark扮演着举足轻重的目标驱动作用。那么如何从0到1构建一个benchmark呢?本文来一起探讨。
什么时候需要构建benchmark
场景1:评测迭代模型:我训练了一个网页抽取模型,想知道它在抽取效果方面的性能以及它目前在什么方面还有欠缺;
场景2:辅助模型选型:我想选一个在视频理解方面比较厉害的推理模型,现有的评测结果指导性不足;
Benchmark是AI产品/模型的自动化测试用例。
构建benchmark流程
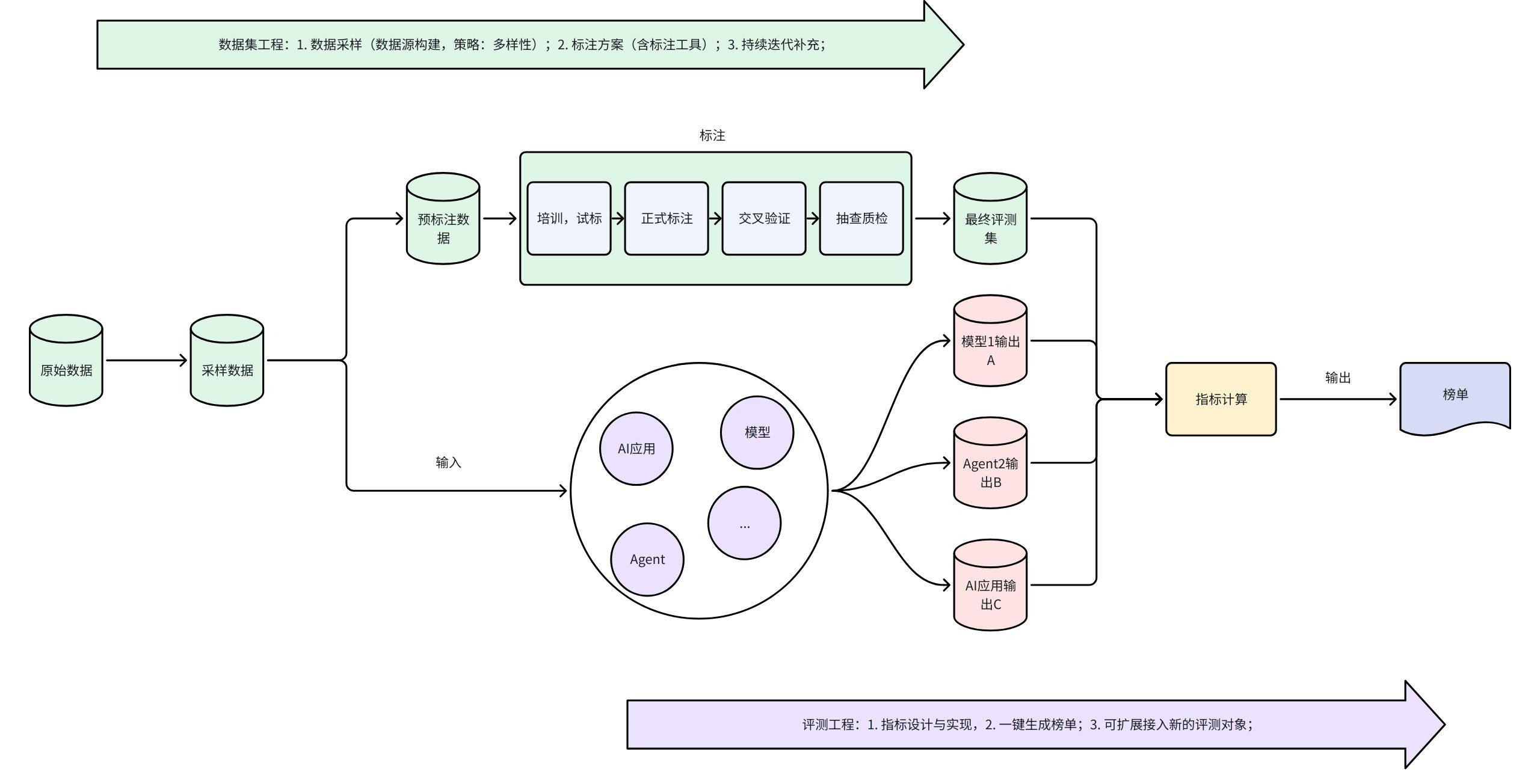
构建一个行业认可的Benchmark工作很繁杂,总结来讲主要分为数据集工程和评测工程两条线。如上图所示。
目标分析
定义需要评测目标;
- 针对评测什么能力,决定需要什么样的数据以及需要什么样的指标;
数据集工程
数据集来源
数据集的数据来源一般有3种方式:
- 全人工构建(最耗费资源的方式)。
- 使用LLM进行Self-Instruct合成。不过,调API合成的数据通常存在多样性较差的问题,那么就需要在构建数据的过程中设计一些技巧,比如提供一个模板,提供更丰富的背景,提高temperature等,让模型生成更丰富的数据。
- 网络爬取 & 现有数据集的整合重组 & 采购等。网络爬取需要注意版权纠纷、数据脱敏的问题,现有数据集的重组就比较简单。
数据集采样策略
采样需要关注下面两项策略:
- 多样性;
- 难易度;
数据集标注
数据集标注一般会比较耗时耗力,主要流程如下:
- 书写标注方案(可迭代)
- 选择标注工具
- 组织标注:多轮质量把控(做不到100%完美)
- 培训,试标;
- 正式标注;
- 背靠背(交叉)审核;
- 抽查质检;
评测工程
评测指标
- 原则:算法严谨,客观,有区分度;
- 一般有3种类型:
- 基于规则。比如True/False,或者选择题,或者进行子串匹配;
- 基于Metric。比如编辑距离,BLEU,PPL这些常用的Metric,通常还会对这些Metrics进行组合,提出一个新的Metric;
- 基于LLM。比如GPT进行Zero-Shot和ICL这些闭源模型进行评分;
评测榜单
评测榜单是否合理,主要是回答为什么这个指标高了,为什么低了,是不是符合预期。如何分析呢?一般可以采用下面的方法:
- 人工;
- 借助分析工具,比如dingo等
论文角度
如果构建的benchmark希望能中顶会paper,主要考虑贡献度:
- 提出解决问题的方法:比如我做一个网页正文内容抽取的评测,那么我需要额外提出一个在这个方向抽取比较的模型方法。比如SWE-bench刚提出来,普遍模型都扑街了,作者也微调了llama来提升一方面的能力。
- 提出新的评测方法:过去的方法可能是昂贵的、速度慢的、不准确的或者狭隘的、与现实情况有偏差的,所以可以提出一个新的可以解决上述问题的方法。比如OnimidocBench中提出的新的评估共识的CDM指标。
- 实验及分析:评测结果需要有一些insight,一些常用的方法:
- 聚类。对评测的对象进行聚类,寻找某个方面的共性。那么就会存在共性–结果趋势上的联系。
- 消融。有一些很常见的消融思路,比如说Model Size,Direction,training dataset等。
- 异常。寻找异常结果,比如最好的、最差的。